Structure Definitions for Binary Files
When dealing with binary file formats, sometimes, one has to look at the raw bits and bytes with a hex editor, especially when debugging a file writer or parser. Reinterpreting the hex numbers to the structures and values in the file format is very tedious. You have to keep all the value offsets and their types in mind to come to the right conclusion. An advanced feature of Okteta, KDE’s hex editor, are structure definitions which describe the data layout of the file format such that the GUI can visualize the values and structures contained in the file.
I made use of it recently when adding perf profiling support to a just-in-time (JIT) engine.
The JIT engine has to dump the generated code to a file in a special format called jitdump before executing the code.
The details of the format are not important for the context of this blog post.
It just serves as the running example.
Using Structure Definitions
First, we will see the structures tool in action. All you need is the hex editor Okteta, an example jitdump file and the structure definition for file format. The definition consists of two files which you have to install manually, see the documentation. For me it boils down to the following two commands.
$ git clone https://github.com/tetzank/asmjit-utilities
$ mkdir -p ~/.local/share/okteta/structures/
$ ln -s $PWD/asmjit-utilities/perf/jitdump-structure ~/.local/share/okteta/structures/
Now you just need to download the example file, decompress it and open it in Okteta.
$ wget https://tetzank.github.io/files/jit-376583.dump.xz
$ unxz jit-376583.dump.xz
$ okteta jit-376583.dump
In the bottom right you will see the panel of the structures tool. It might be empty at the moment. We have to enable the structure definition first. Click on “Settings” at the bottom of the panel and then “Structures Management”. Now, click the checkbox next to the jitdump definition. After applying the changes, you should see a jitdump entry in the structures panel. You can unfold the levels to see the file header and a list of records of various types. Here is a screenshot.
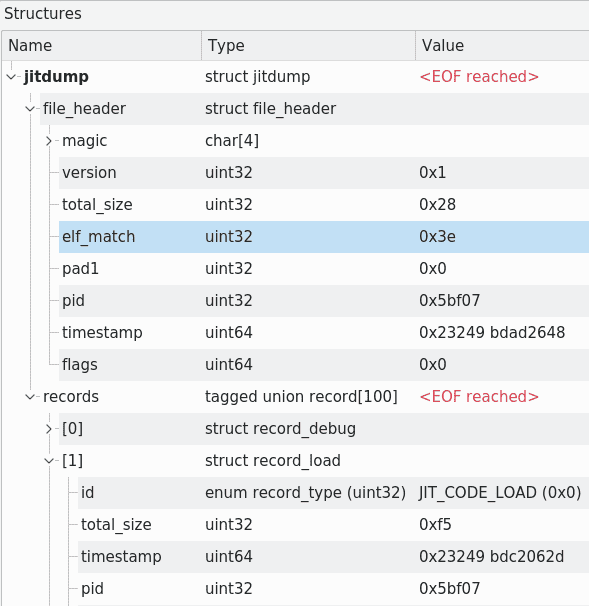
In “Settings” you can also change how numerical values are displayed, in decimal or hexadecimal. Furthermore, you can conveniently download new definitions from a central server. Unfortunately, there are not many definitions available. This feature seems to be a hidden gem not many people know about.
Each value can be accessed and modified. It makes debugging of binary files very easy as the file is parsed for you by the hex editor.
Writing Your Own
In this section we will have a look at how you can write your own structure definitions for the file formats you are interested in. A good start is Okteta’s documentation, and KDE’s userbase wiki which helped me a lot with some of the nitty details. I will walk you through the things I did for the jitdump definition.
A structure definition consists of two files: metadata.desktop, and main.osd or main.js depending which on the type of the definition.
We will focus on the JavaScript type as it allows us to change the data layout of the structures dynamically during parsing.
metadata.desktop
The name, description and type of the structure definition is stored in this file.
A .desktop file is pretty simple and similar to a .ini file.
There is a key-value-pair per line and the section heading “Desktop Entry” on the first line.
[Desktop Entry]
Encoding=UTF-8
Icon=application-x-executable
Type=Service
ServiceTypes=KPluginInfo
Name=JitDump Structure
Comment=Structure of the JitDump format for perf
X-KDE-PluginInfo-Author=Jane Doe
X-KDE-PluginInfo-Email=jane.doe@converge.rock
X-KDE-PluginInfo-Name=jitdump
X-KDE-PluginInfo-Version=0.1
X-KDE-PluginInfo-Website=https://github.com/tetzank/asmjit-utilities
X-KDE-PluginInfo-Category=structure/js
X-KDE-PluginInfo-License=MIT
X-KDE-PluginInfo-EnabledByDefault=falseMost entries should be quite self-explanatory.
Make sure to set Name and Comment to the right name and description of your structure definition.
The type is set to JavaScript by X-KDE-PluginInfo-Category=structure/js.
(The other option would be X-KDE-PluginInfo-Category=structure.)
main.js
The actual definition lives in this file. The jitdump format consists of a header data structure followed by an unspecified number of records, until the end of the file (EOF). The structure definition is constructed in the init function of main.js.
function init(){
var file_header = //... snip ...
var record = //... snip ...
var jitdump = struct({
header : file_header,
records : array(record, 100) //FIXME: size hardcoded, no length in format, read until EOF
});
jitdump.defaultLockOffset = 0;
return jitdump;
}
We use the function struct() to define a data structure similar to C/C++.
It has two members: header of type file_header and records, an array of record elements using the function array(type, length) to define it.
The array length is hardcoded to 100 elements as I do not know a way to grow it dynamically until the end of the file.
We still have to specify both types file_header and record.
Let us define the header structure file_header next.
Here’s the C/C++ definition.
struct header{
uint32_t magic;
uint32_t version;
uint32_t total_size;
uint32_t elf_mach;
uint32_t pad1;
uint32_t pid;
uint64_t timestamp;
uint64_t flags;
};
The definition is pretty straightforward.
We use struct() again with all the members listed above, using pre-defined functions uint32() and uint64() to specify the integer types.
var file_header = struct({
magic : array(char(), 4),//uint32(),
version : uint32(),
total_size : uint32(),
elf_match : uint32(),
pad1 : uint32(),
pid : uint32(),
timestamp : uint64(),
flags : uint64()
});
file_header.name = "file_header";
Looks pretty similar to the C++ code, doesn’t it?
The member magic is either 'JitD' or 'DTiJ' depending on the endianness of the architecture.
To make it display as characters, I changed the type to a fixed-size array of char().
The record type is a bit more complicated.
It actually represents a family of types, consisting of a common record header followed by various payloads, depending on the record type.
Another way to look at it: a structure containing a union of payload types.
struct record{
// common fields of record header
uint32_t id;
...
// payload, only one is active as indicated in id
union{
struct { ... } record_load;
struct { ... } record_debug;
...
};
};
This is called a tagged union which is quite common in data formats.
The convenience function taggedUnion() provides support for such structures.
var record = taggedUnion(
// common fields
record_header,
[ // list of alternatives of union
record_load,
record_debug
]
);
Now, we just have to define all the fields and alternatives. Let’s start with the common fields: the record header.
enum record_type : uint32_t {
JIT_CODE_LOAD = 0, // describing a jitted function
JIT_CODE_MOVE = 1, // already jitted function which is moved
JIT_CODE_DEBUG_INFO = 2, // debug info for function
JIT_CODE_CLOSE = 3, // end of jit runtime marker (optional)
JIT_CODE_UNWINDING_INFO = 4 // unwinding info for a function
};
struct record_header{
enum record_type id; // record type
uint32_t total_size; // size in bytes of record including header
uint64_t timestamp; // creation timestamp of record
};
The record header consists of three fields: id, total_size and timestamp.
id is an enum type indicating which kind of type this record is.
To print the identifier of the enum entry, we define the enum in JavaScript as well and use the pre-defined function enumeration(name, base_type, enum_type).
var record_type = {
JIT_CODE_LOAD : 0, // describing a jitted function
JIT_CODE_MOVE : 1, // already jitted function which is moved
JIT_CODE_DEBUG_INFO : 2, // debug info for function
JIT_CODE_CLOSE : 3, // end of jit runtime marker (optional)
JIT_CODE_UNWINDING_INFO : 4 // unwinding info for a function
};
var record_header = {
id : enumeration("record_type", uint32(), record_type),
total_size : uint32(),
timestamp : uint64()
};
We will not define all record types, only JIT_CODE_LOAD and JIT_CODE_DEBUG_INFO as they are the most important ones.
Let us see the load record next.
var record_load = alternative(
// selectIf
function(){ return this.wasAbleToRead && this.id.value == record_type.JIT_CODE_LOAD; },
{
pid : uint32(),
tid : uint32(),
vma : uint64(),
code_addr : uint64(),
code_size : uint64(),
code_index : uint64(),
function_name : string("ascii").set({terminatedBy : 0}),
native_code : array(uint8(), function(){ return this.parent.code_size.value; })
},
"record_load"
);
We use alternate() to define a union entry which takes as the first parameter a selection function.
It checks if the entry should be active or not.
We check with this.wasAbleToRead for parsing errors and then compare the value of id in the record header with JIT_CODE_LOAD.
In this context, this refers to current structure under construction, which is the tagged union.
We can access everything which is already parsed.
The load record contains a null-terminated string function_name.
We define it with the function string(encoding) and set additionally terminatedBy to null.
Immediately after the string follows the memory buffer for the generated function code.
We use an array of bytes to represent it.
The array size is defined in the field code_size.
We pass a function to array() which extracts the size dynamically when the array is constructed.
Here, this refers to the array we are constructing which means we have to get to the parent structure first before accessing the value of code_size.
Now that we know all of this, the definition of the debug info record is straightforward.
var debug_entry = struct({
code_addr : uint64(),
line : uint32(),
discrim : uint32(),
name : string("ascii").set({terminatedBy : 0})
});
debug_entry.name = "debug_entry";
var record_debug = alternative(
// selectIf
function(){ return this.wasAbleToRead && this.id.value == record_type.JIT_CODE_DEBUG_INFO; },
{
code_addr : uint64(),
nr_entry : uint64(),
entries : array(debug_entry, function(){ return this.parent.nr_entry.value; })
},
"record_debug"
);
Arrays can also consist of aggregate types.
We define the element type first and pass it as first parameter to array(type, size).
That’s pretty much it. We can make the code a bit more concise by specifying the whole record type at once with nested expressions.
var record = taggedUnion(
{ // record header
id : enumeration("record_type", uint32(), record_type),
total_size : uint32(),
timestamp : uint64()
},
[ // alternatives depending on record type marked in id
alternative(
// selectIf
function(){ return this.wasAbleToRead && this.id.value == record_type.JIT_CODE_LOAD; },
{
pid : uint32(),
tid : uint32(),
vma : uint64(),
code_addr : uint64(),
code_size : uint64(),
code_index : uint64(),
function_name : string("ascii").set({terminatedBy : 0}),
native_code : array(uint8(), function(){ return this.parent.code_size.value; })
},
"record_load"
),
alternative(
// selectIf
function(){ return this.wasAbleToRead && this.id.value == record_type.JIT_CODE_DEBUG_INFO; },
{
code_addr : uint64(),
nr_entry : uint64(),
entries : array(debug_entry, function(){ return this.parent.nr_entry.value; })
},
"record_debug"
),
]
);
record.name = "record";
Looks kind of neat. And that is rare for me to say about JavaScript code…
Conclusion
I like this tool very much. The definitions are easy to write and the visualization of the data layout inside the hex editor helps tremendously. JavaScript is definitely not my favorite programming language, but it gets the job done and is more flexible than the XML definition.
For me, this is the fastest way to write a parser for a binary data format and get a graphical interface for free. I’m glad to have it in my toolset.